
Summary
This article describes the challenges that internet scale enterprises face and gives an overview of an architecture to deal with those challenges. We will delve into the components of this architecture in subsequent articles.
Introduction
At the end of 2018, three of the world’s top five companies by market capitalisation are Amazon, Alphabet (Google) and Facebook. Blockbuster, a once mighty chain of video stores, has been driven by relentless competition from Netflix to close down its stores until only a single store remained in Bend, Oregon.
The disruption caused by Netflix to traditional brick-and-mortar stores is not unique; similar havoc has been caused by Uber, a taxi company that does not own any taxis, and by Airbnb, a hotel company that does not own any hotels. The thing the FANGs (Facebook, Amazon, Netflix and Google) all have in common is that they are technology companies, and in particular internet companies, that have only come into being in the last decade or so, and that they operate at internet scale.
Operating at internet scale means:
- Very high transaction volumes, usually thousands of transactions per second
- Geographic distribution – these companies operate with a global customer base
- Big data – exabytes of data or more
- Having to scale rapidly on demand – like Amazon Black Friday or Amazon Prime Days
- Safely and quickly bringing new products to market
- Protecting against the threats of a global army of bad guys
- Being ‘always on’ – there is no room for maintenance windows
If you have already worked for an internet scale enterprise (a ‘unicorn’), you should have a good idea of how to architect for internet scale. If you are an architect who works for a traditional enterprise (a ‘horse’), you might think that you don’t need to concern yourself with architecting for internet scale – but you’d be wrong! Traditional enterprises embark on digital evolution journeys that integrate currently disparate services globally across a large number of customers. They may also be faced with operating 24/7 or opening up closed internal APIs to the public.
This article references a number of open source and commercial tools. They are examples with which I gained experience in a specific project context. It is not meant to favour one tool over another.
Internet scale deployment stack
Overview
In the last few years, I have been involved in the ongoing development of an internet scale architecture for a traditional enterprise. In this article, I will give an overview of the logical building blocks of an internet scale architecture based on projects that I have been involved in.
In subsequent articles, I will look at particular solution choices that I have direct experience with. I’m assuming the use of the REST architectural style with JSON/HTTP(S) implemented. The constraints of the REST architectural style naturally lead to scalability being a property as shown in [1]. The layers of the logical architecture are shown in Figure 1:
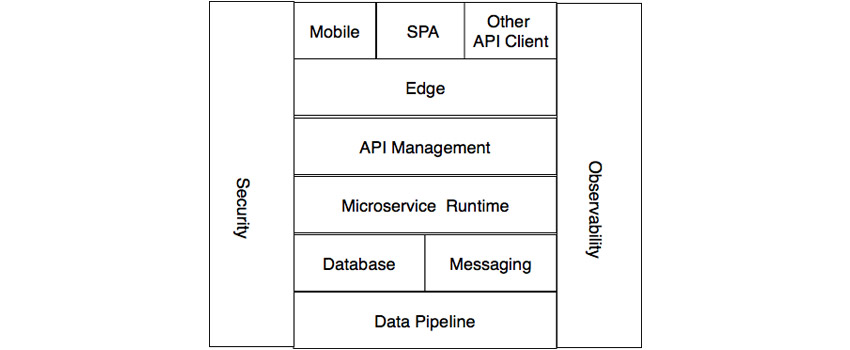
Figure 1: Layers of the logical architecture
A possible deployment is shown in Figure 2:
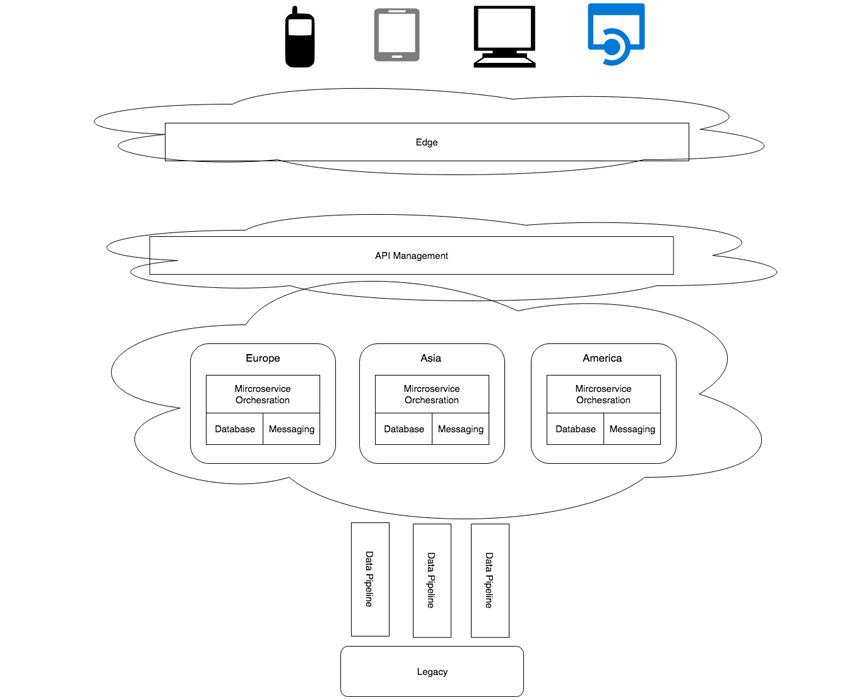
Figure 2: Possible deployment
In the following sections, I will present the different elements of the internet scale deployment stack.
Client
Our architecture is based on clients consuming REST services. Broadly speaking, the clients will fall into one of the following categories:
- Browser-based single page applications (SPA) developed using a JavaScript framework such as Vue, React or Angular
- Native mobile applications running under iOS or Android
- Other native API clients, for example server applications that consume third-party services
Edge
You’re architecting for internet scale, which means a worldwide user base who expects their applications to load and respond quickly. You need to serve up content and data as close as possible to the user. Figure 2 illustrates how we distribute our core services and data over a number of geographic regions, so we require some form of global load balancing. It is useful, though, to do as much processing as we can even closer to the user than merely being in the same geographic region. For example, serving up static content, such as images or perhaps slowly changing reference data.
Your applications are undoubtedly going to be very attractive to a large class of bad hats. I’ve seen an API go live and get hit with a DDoS attack in mere minutes. A good way to deal with these sorts of threats is to head them off as close to their source as possible.
In a subsequent article, I will look at a suite of services from Akamai that I class as edge services. These include:
- Distributed reverse proxies
- Content delivery
- Global traffic management / load balancing
- DDoS protection
- Bot protection
- Caching
These Akamai services are executed relatively close to the user, often in the same data centre as the user’s ISP.
API management
Enterprises I have worked with have adopted an API-first approach, building product teams around the delivery of REST APIs and creating an economy of API consumers. If your product is successful, you will have many potential users who want to use your APIs. You want to be able to:
- Provide clear and comprehensive documentation of your APIs
- Provide a self-service capability for prospective users to obtain access to APIs by obtaining credentials and authorisation grants
- Monetise your APIs. This will likely involve creating usage plans which limit the number and frequency of API requests depending on how much the customer will pay, usually with a free plan for a limited number of requests
- Provide a sandbox environment, for customers to test their API clients
Microservice runtime
As described in [2] and [3], scaling an application involves applying a scaling strategy in one or more of these three axes:
- x-axis - run multiple copies of the same application
- y-axis - decompose the application into functionally separate components
- z-axis - partition the data
The most commonly used approach to y-axis scaling is to adopt a microservices architecture. This often incorporates a degree of z-axis scaling as well since microservices often have their own distinct data stores. I’m going to assume a microservices architecture, given the desirable y- and z-axis scaling. I’ll discuss microservices in more detail in a dedicated article, but for the purpose of this article, we’ll note that microservices are small, independently deployable and testable services organised around business capabilities that interact in a loosely coupled fashion. The environment in which they are deployed is the microservice runtime.
Now, to make things more scalable, we want to apply some x-axis scaling to our microservices. We want to be able to do things like:
- Scale up as demand increases
- Scale down as demand decreases, so we can save run costs
If we’re running many thousands of replicas, then the failure of a microservice or the hardware it runs on is basically guaranteed. Also, we cannot manually assign microservices to compute nodes or manually configure load balancers, so we need automation to do the following:
- Restart failed microservice instances
- Assign microservices to compute nodes
- Automatically configure load balancers
We can pretty much take it as a given that our microservice runtime will be some form of container, usually a Linux container, such as Docker. There are essentially two approaches to achieving the capabilities we have listed above. The first is a Platform-as-a-Service approach (PaaS), in which we are not aware of the containers. In the second approach, we have a platform that we use directly to schedule and manage containers.
An example of the first is CloudFoundry, which has a number of implementations, for example Pivotal CloudFoundry. An example of the second is Kubernetes, which is available as a service on the Google Cloud Platform, Azure and IBM Cloud, as well as an on-premises solution.
Persistence
Persistence comes in various flavours – from traditional relational database management systems (RDMS) to modern NoSQL datastores. Relational databases ruled the roost for a few decades but proved difficult to scale.
Scalability on the x-axis usually ends up being challenged by the necessity of having some form of shared storage, especially for stateful services. Via sharding of data, z-axis scalability is normally done using very application-specific strategies. If you’re operating at internet scale, you will likely want some or more of the following properties:
- Zero downtime, including when upgrading
- Ability to cluster across geographic regions
- Ability to grow to very large sizes
These are either qualities that are not normally associated with an RDMS or that are very expensive to achieve. We can achieve all of these (and more) together with the x and z axis scaling using Cassandra, a linearly scalable, peer-to-peer, shared-nothing database.
Messaging
Highly scalable applications often employ asynchronous processing since this reduces the number of processes that are in a waiting state as requests are processed. So, we will want to include a messaging capability in our architecture. We will look at Kafka, which is not only a message-oriented middleware but also a distributed, consistent log, which makes it an implementation option for an event-sourced architecture [4].
Data pipeline
It is unlikely that you are going to be on an entirely greenfield project, so we need mechanisms to integrate with traditional enterprise applications. In a future article, we will deal with building a data pipeline from enterprise applications using Oracle Goldengate, Oracle Goldengate for Big Data and Apache Spark.
Security
Security is a very important topic, and we cover some security perspectives of an internet scale architecture in other articles. We will really only scratch the surface, looking at Oauth2, OIDC and perhaps network and container security in Kubernetes.
Observability
We’ve ended up with a very complex, distributed system, which poses distinct operational challenges over and above those of a traditional monolithic system. Understanding how the system is performing and whether the system is behaving as it should is critical, as is being able to troubleshoot issues when they occur. We will look at Prometheus, which is a monitoring tool particularly well-suited to Kubernetes environments, and ELK, a centralised log aggregation and analysis tool. If I have not died of old age, we will also look at Zipkin for distributed tracing.
Conclusion
As we have seen, internet scale architectures are needed by more than just the unicorns of the digital world, and the building blocks of such architectures are now within reach of architects working within more traditional enterprises. In subsequent articles, we will delve more deeply into each of the areas we touched upon in this article, drawing upon hard-won personal experience. See you soon!
References
[1] Architectural Styles and the Design of Network-based Software Architectures, Dissertation, Roy Fielding, 2000
[3] The Art of Scalability: Scalable Web Architecture, Processes and Organizations for the Modern Enterprise, Martin Abbot and Michael Fisher, 2010
[4] CQRS Documents, Greg Young